AI Agent란
AI Agent가 동작하는 방식에 대한 조사
AI Agent
AI Agent(agentic AI)는 최근 마케팅 용어처럼 사용되기도 하지만, 본질적으로 LLM이 자체 판단으로 목표 달성을 위해 도구/다른 AI를 활용해 인간을 지원하는 시스템입니다. 단순 반복 작업부터 복잡한 문제 해결까지, 학습 능력과 환경 적응성을 바탕으로 다양한 역할을 수행합니다. LangChain, LangGraph, AutoGen 등 기존 AI 워크플로우를 발전시킨 형태가 현재의 AI Agent로 불립니다.
AI Agent와 기존의 ChatGPT 같은 LLM 서비스의 차이점은 목적과 능력에 있습니다.
기존의 LLM 서비스의 경우, 기본적으로 챗봇의 형태로 인간과 상호작용 하도록 설계되었습니다.따라서 인간을 보조하기만 할 뿐, 자율적인 행동을 취하지 않습니다. 하지만 AI Agent는 목표를 위해 자율적인 작업을 수행합니다. 무엇을 해야할지 절차지향적으로 계속 지시할 필요 없이, 선언적으로 어떤 목표를 지시하면, 그 이후의 과정은 Agent가 알아서 방법을 찾아 목표를 완수합니다.
AI Agent의 동작 방식은 작업의 복잡성과 유형에 따라 다양한 구조로 구성될 수 있으며, 각 구조는 고유한 장점과 한계를 가지고 있습니다. 대표적인 AI Agent의 동작 방식들을 자세히 살펴보겠습니다.
1) Augmented LLM
가장 기본적인 Angent의 형태이며, retrieval, tools, memory와 같은 augmentations로 강화된 LLM입니다. LLM은 자체적으로 search queries를 생성하고, 적절한 tool을 선택하며, 어떤 정보를 보존할지 결정할 수 있습니다. 예를 들어 전자상거래 챗봇은 사용자 질문 분석 → 제품 데이터베이스 검색 → 주문 내역 확인 → 결제 시스템 연동을 하나의 흐름으로 처리할 수 있습니다.
이것이 Simgle Agent로써, 추후 여러 Agent와 결합하거나 다양한 구조를 만들어내며 복합적인 문제를 해결하는 AI Agent로 발전하게 됩니다.
# 전자상거래 지원 에이전트 예시
response = llm.generate(
tools=[product_db, order_history, payment_system],
memory=user_conversation_log,
query="지난주에 주문한 스마트워치 교환 방법 알려줘"
)

해당 형태는 use case에 대해 tailoring(맞춤 조정)하고, LLM에 대해 쉽고 잘 문서화된 인터페이스를 제공하는지 확인하는 것이 좋습니다.
장점: 간단하고 빠르게 더 똑똑한 AI를 만들 수 있습니다.
한계: 복잡한 문제를 해결할 때, 하나의 LLM으로 해결하기 어려울 수 있습니다.
사용 사례:
- 간단한 챗봇 서비스
- 고객 상담 응대
2) Propmt Chaining
Prompt Chaining은 복잡한 문제를 순차적 단계로 분해하여 LLM 호출을 연결하는 방식입니다. 특히, 중간 단계에 프로그래밍 방식의 Check(아래 다이어그램의 “Gate”를 참조)를 추가하여 프로세스가 계속 잘 진행중인지 확인할 수 있습니다. 예를 들어, 마케팅 콘텐츠 생성 시스템에서는 1) 타겟 분석 → 2) 키워드 추출 → 3) 초안 작성 → 4) 문체 조정의 단계를 거치며, 각 단계 결과가 다음 단계의 입력으로 사용됩니다.
# 마케팅 콘텐츠 생성 파이프라인
target_analysis = llm("타겟: 20대 여성, 제품: 에코백 분석")
keywords = llm(f"{target_analysis} 기반 키워드 추출")
draft = llm(f"{keywords} 포함한 초안 작성")
final = llm(f"{draft}를 캐주얼한 문체로 리라이팅")
해당 형태는 task를 고정된 subtask로 쉽고 깔끔하게 분해할 수 있는 상황에 사용하기 좋습니다. 즉, 각 LLM call을 더 쉬운 task로 만들어서, latency를 줄이고 정확도를 높이는 것입니다.
장점: 복잡한 일을 정확히 처리할 수 있습니다.
한계: 단계가 많아지면 시간이 오래 걸립니다.
사용 사례:
- 논문 작성 후 검수
- 마케팅 위한 자료 조사 후 콘텐츠 생성
3) Routing
Routing은 Input 유형을 실시간 분류하여 최적의 처리 경로로 안내하는 시스템입니다. 각각 전문화된 AI에게 전달하는 것인데, 예를 들어 병원에서 환자를 치료할 때 의사들이 전문 분야별로 환자를 나누는 것과 같습니다. 또는 고객 지원 시스템에서는 자연어 처리(NLP)를 통해 문의 내용을 12개 세부 카테고리로 분류하고, 각 전문 하위 에이전트에게 할당하는 예시가 있습니다
def route_query(query):
category = llm.classify(
query=query,
categories=["결제", "배송", "제품문의", "A/S", "기타"]
)
if category == "결제":
return payment_agent.handle(query)
elif category == "배송":
return shipping_agent.handle(query)
#...
해당 형태는 개별적으로 처리하는 것이 더 나은 뚜렷한 카테고리가 있고, LLM이나 보다 전통적인 분류/모델 알고리즘으로 분류를 정확하게 처리할 수 있는 복잡한 작업에 적합합니다.
장점: 정확하고 효율적으로 문제를 해결할 수 있습니다.
한계: 입력 유형이 잘못 분류되면 문제가 생길 수 있습니다.
사용 사례:
- 다양한 유형의 고객 서비스 문의(일반 문의, 환불 요청, 기술 지원)를 서로 다른 프로세스, 프롬프트 및 툴로 안내
- 의료 상담
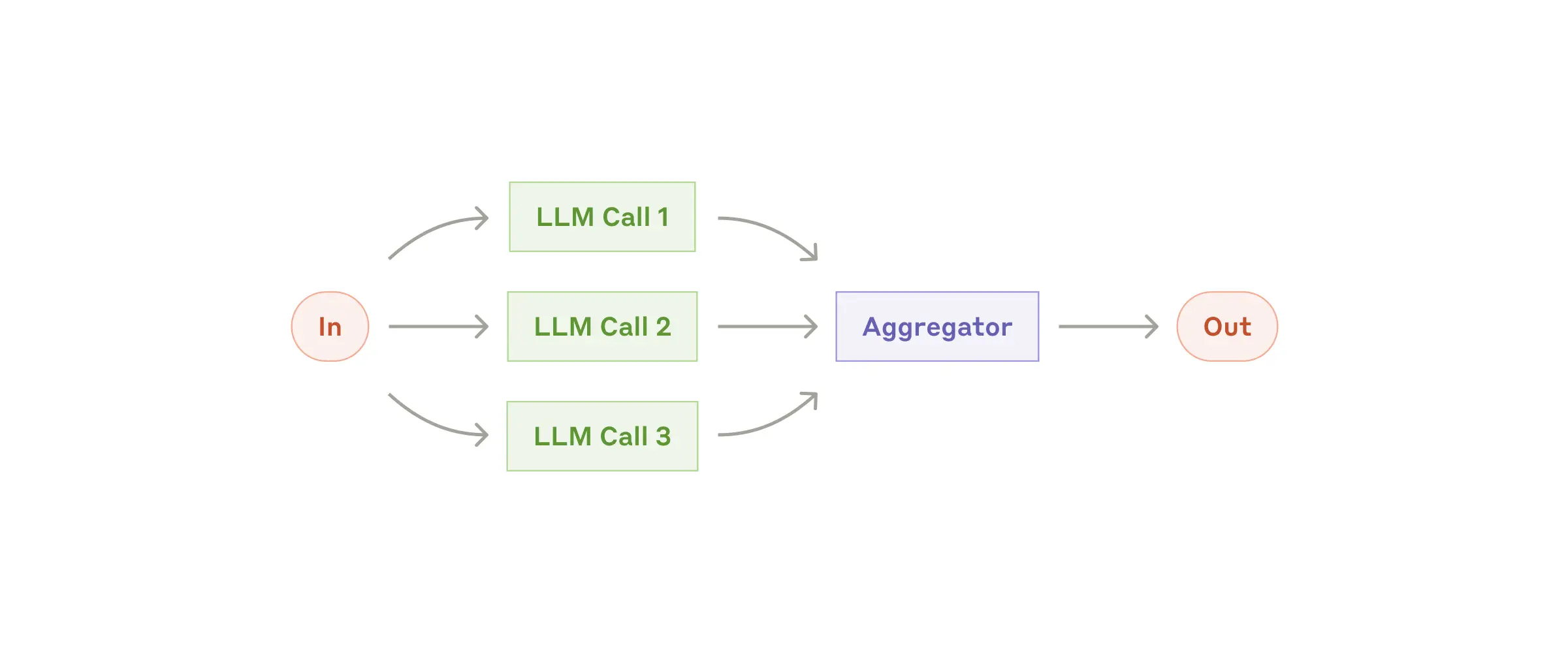
4) Parallelization
Parallelization은 작업을 동시에 다중 처리하여 신뢰성과 속도를 향상시키는 접근법입니다. 혹은 한 가지 작업을 여러 번 수행해 신뢰도를 높이는 방식으로 쓰이기도 합니다. 쉽게 말해 친구들과 함께 숙제를 나눠서 빠르게 끝내는 것일 수 있고, 콘텐츠 생성 시스템에서는 본문 작성과 동시에 안전성 검증을 수행하며, 3개의 독립적 분석 모듈이 투표 방식을 통해 최종 결정을 내립니다.
아래 그림에서 Aggregator가 동시에 작업한 결과물을 프로그래밍 방식으로 집계하는데, 두가지 주요 변형으로 나타납니다.
- 섹션화: 작업을 병렬로 실행되는 독립적인 하위 작업으로 나누는 것
- 투표: 동일한 작업을 여러 번 실행하여 다양한 결과물을 얻는 방법
# 동시에 여러 AI에게 같은 질문을 하여 가장 좋은 답을 고릅니다.
answers = [AI.ask(question) for AI in AI_list]
best_answer = choose_best(answers)
# Thread를 사용한다면
from concurrent.futures import ThreadPoolExecutor
def generate_content(topic):
with ThreadPoolExecutor() as executor:
future1 = executor.submit(llm, f"{topic}에 대한 기사 작성")
future2 = executor.submit(llm, f"{topic}의 윤리적 검증")
return {
"content": future1.result(),
"safety_check": future2.result()
}
장점: 작업을 빠르고 정확하게 처리할 수 있습니다.
한계: 자원이 많이 소모될 수 있습니다.
사용 사례:
- 복잡한 데이터 분석
- 코드 보안 검사
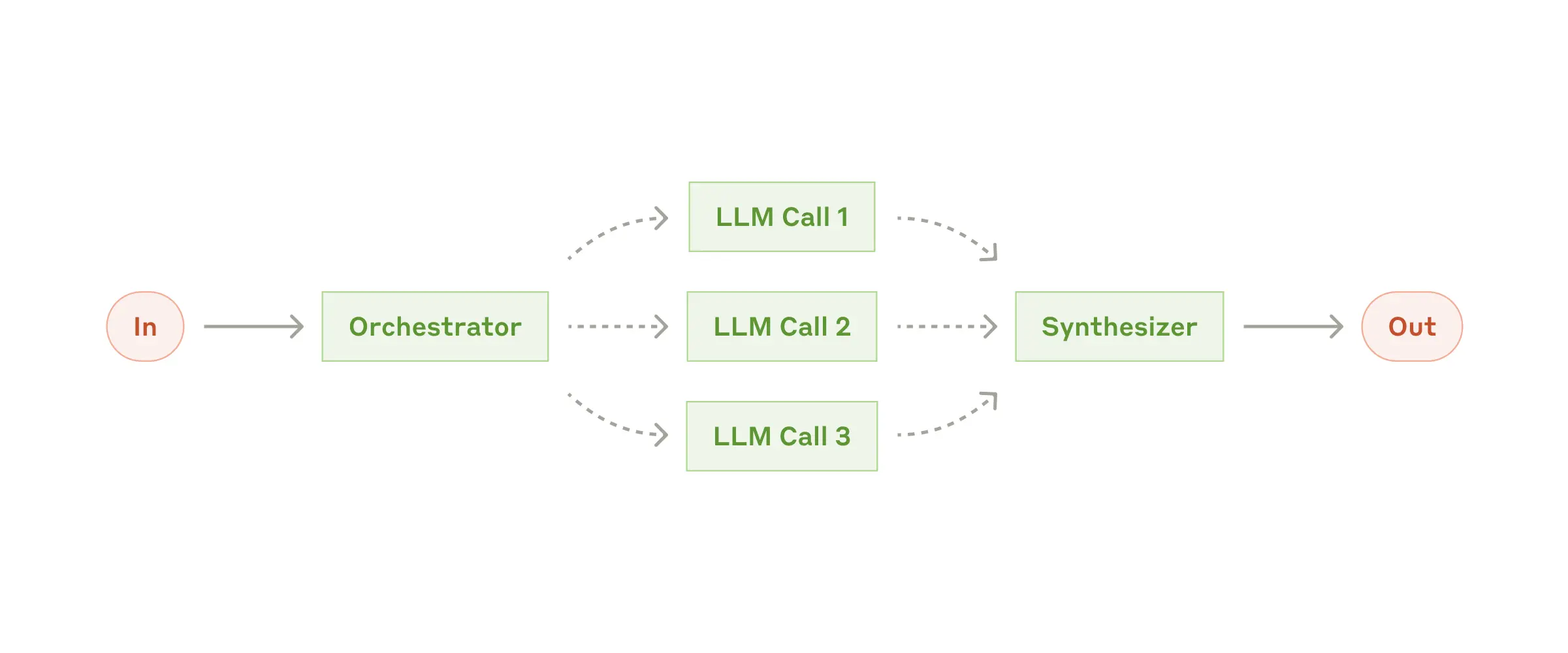
5) Orchestrator-workers
중앙 조정자(Orchestrator)가 복잡한 작업을 동적으로 분해하고 관리하는 아키텍처입니다. 중앙 LLM은 작업을 “동적으로 세분화”하여 워커 LLM에 위임하고 그 결과를 종합합니다. 이 구조는 필요한 하위 작업을 예측할 수 없는 복잡한 작업에 적합합니다. 4) Parallelizaion과 비슷한 구조처럼 보일 수 있지만, 앞서 말한 “동적으로 세분화”했다는 것이 다릅니다. Parallelizaion은 하위 작업을 미리 정해놓고 병렬처리를 하지만 Orchestrator-workers 구조에서는 하위 작업을 미리 정의하지 않고, 특정 입력에 따라 Orchestrator에 의해 결정됩니다.
예를 들어, 코딩 에이전트의 경우 변경해야 하는 파일이 복잡하고 매 작업마다 달라질 수 있습니다. 코드 리팩토링 시스템에서는 메인 에이전트가 전체 구조를 분석한 후, 개별 파일 수정 작업을 워커 에이전트에게 분배합니다.
# Orchestrator가 작업을 나누고 워커의 결과를 모읍니다
sub_tasks = orchestrator.divide_task(big_task)
results = [worker.solve(task) for task in sub_tasks]
final_result = orchestrator.combine(results)
장점: 유연하게 문제를 해결할 수 있습니다.
한계: 워커 간의 협력이 잘 이루어지지 않으면 효율이 떨어질 수 있습니다.
사용 사례:
- 복잡한 코딩 프로젝트
- 여러 소스에서 정보를 수집하고 분석하여 가능한 관련 정보를 찾는 검색 작업.
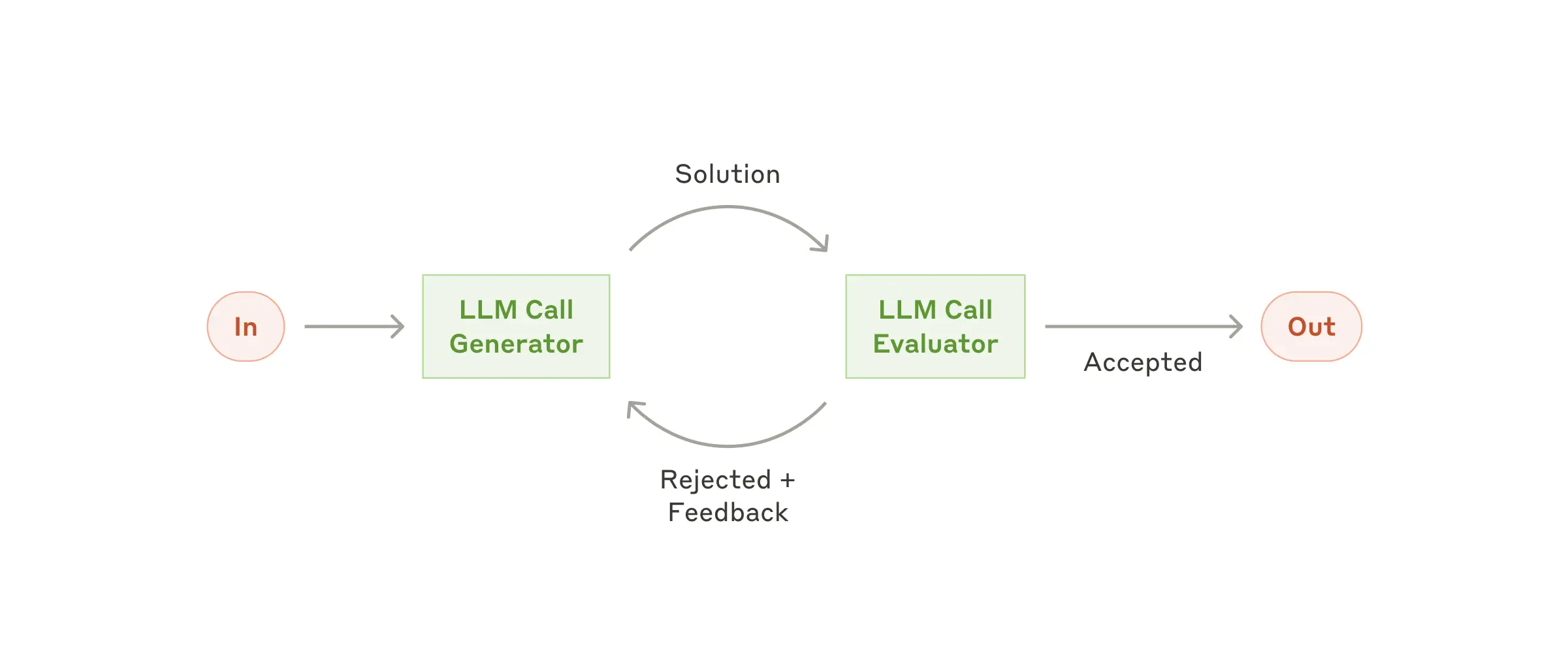
6) Evaluator-optimizer
하나의 LLM 호출은 응답을 생성하고 다른 하나는 평가와 피드백을 반복하는 자기진화형 시스템입니다. 예를 들어, 문서 번역 에이전트는 초안 생성 후 문화적 적절성, 어감, 정확성 측면에서 3단계 평가를 수행합니다. 혹은 작가가 글을 작성할때 거치는 반복적인 글쓰기 과정과도 유사합니다.
명확한 평가 기준이 있고 반복적인 개선을 통해 측정 가능한 가치를 제공할 때 특히 효과적입니다.
// 아래 함수를 반복
def translate_document(text, target_lang):
draft = llm(f"{text} → {target_lang} 번역")
feedback = llm(f"번역품질 평가:\\n{draft}")
refined = llm(f"개선된 번역:\\n{feedback}")
return refined
장점: 결과가 점진적으로 개선됩니다.
한계: 반복이 너무 많으면 시간이 오래 걸릴 가능성이 있기에 주의해야합니다.
사용 사례:
- 번역가 LLM이 포착하지 못한 뉘앙스를 평가자 LLM이 유용한 비평을 제공할 수 있는 문학 번역.
- 포괄적인 정보를 수집하기 위해 여러 차례의 검색과 분석이 필요한 복잡한 검색 작업
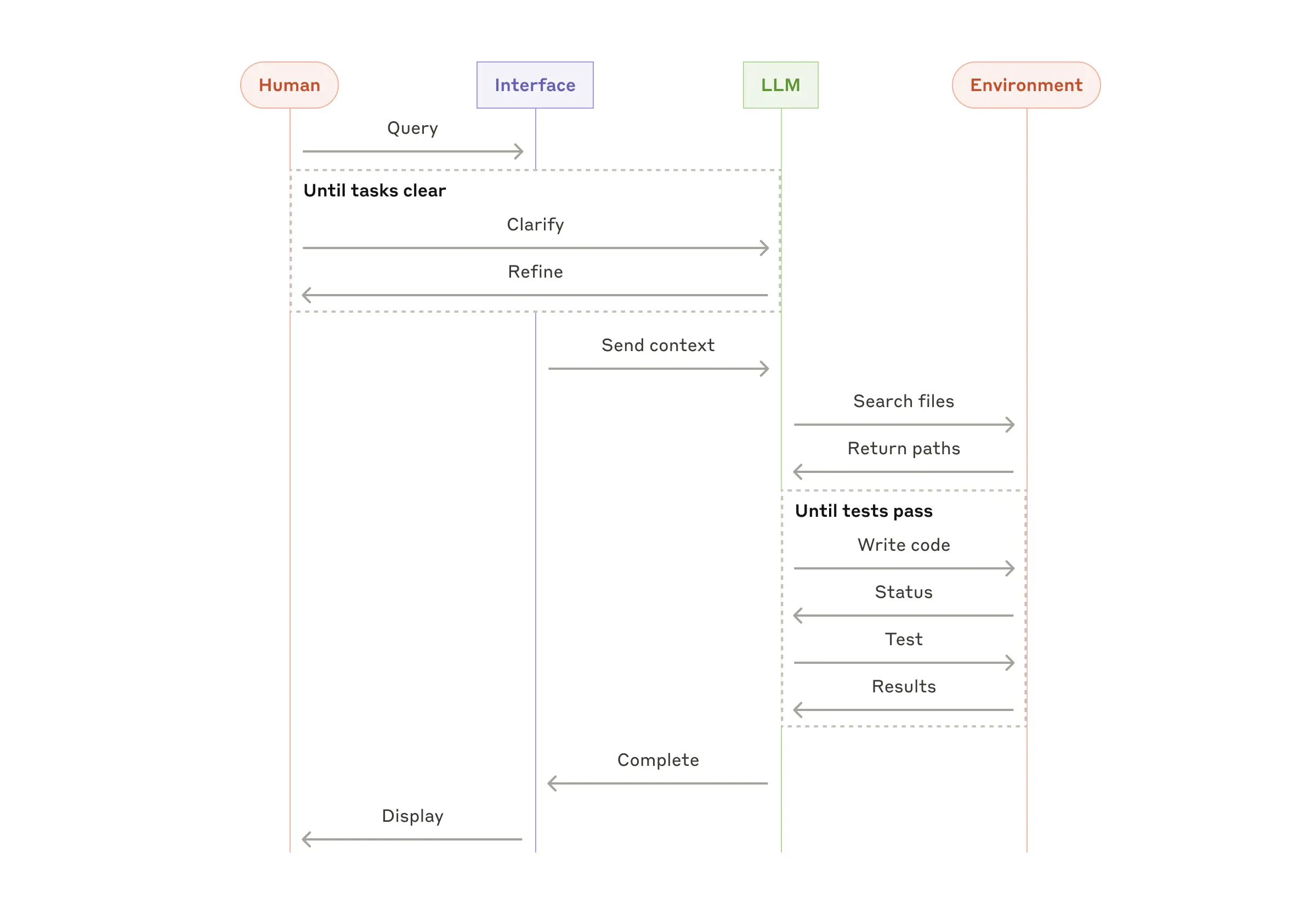
7) Custom Agents
특정 업무 영역에 최적화된 복합 에이전트 구현체입니다.
에이전트가 명령을 받으면 알아서 계획하고 해당 task를 운영하고, 추가 정보가 필요하다면 인간에게 다시 권한 요청이나 문의를 하기도 합니다. 일반적으로는 LLM에이전트의 Action으로 Environment Feedback에 기반해 반복하여 동작합니다. 예를 들어, 아래의 도식을 보면 LLM과 Environment 사이의 상호작용이 반복되고, LLM의 판단으로 작업이 끝나면 인간에게 output을 전달합니다.
이 구조는 필요한 단계 수를 예측하기 어렵거나 불가능하고 고정된 경로를 하드코딩할 수 밖에 없는 open-ended problens에 사용할 수 있습니다. 하지만 에이전트의 자율성이 높아질수록 더 높은 비용과 복합적인 오류 가능성이 올라가기에, 적절한 가드레일과 샌드박스 환경에서 테스트를 수행하는 것이 권장되곤 합니다.
# 특별한 작업을 위한 맞춤 AI
custom_agent = CustomAgent(tool1, tool2)
result = custom_agent.perform_special_task(task)
장점: 상황에 맞는 가장 적합한 AI를 만들 수 있습니다.
한계: 개발자의 기술력에 크게 의존합니다.
사용 사례:
- 특정 회사 업무 자동화
- 특별한 분석 시스템 구축
Web2 AI Agent의 한계점
위와 같이 Web2 환경에서의 AI Agent는 어쨋든 중앙화된 서버에서 동작하며, 사용자 데이터를 수집하고 처리합니다. 이 모든 과정이 특정 기업이나 기관이 통제하는 중앙화된 인프라에서 이루어집니다. 이런 구조에서 데이터 수집 정책 논란이나 개인 정보에 대한 우려가 끊이지 않고 있습니다.
2023년 OpenAI에서는 ChatGPT에서 사용자 대화 기록, 개인 식별 정보를 유출하기도 하고, 삼성의 회사 기밀을 유출하여 삼성에서는 GPT 사용 금지 조치가 내려지기도 했습니다. 2024년 Anthropic의 Claude에서도 외부 협력사 시스템의 취약점을 이용해 특정 사용자 대상 데이터가 유출 되기도 하였습니다. 2025년 1월에는 Deepseek에서는 데이터베이스 노출 이슈로 주가가 급락하는 사건이 있기도 했습니다.
그리고 중앙화된 서비스이기 때문에 ChatGPT서비스가 잠시 서비스를 중단하면 많은 사용자가 피해를 입기도 하였습니다. DeepSeek에서는 중국의 주석에 관련한 민감한 질문을 하면 제대로된 답변을 하지 않았습니다. 즉, 중앙 집중식 LLM인 경우에는 검열이나 편향된 출력 결과를 만들어낼 수 있다는 예시일 것입니다.
이어서 다음 글에서는 Web3에서 AI Agent에 대해 알아보겠습니다.
cf)
https://www.anthropic.com/engineering/building-effective-agents
https://eliza.how/blog/reintroduction